在这里对前段时间所学的pwn相关内容进行简单的整理和总结。
工具篇
主要工具
| 工具名 | 链接 | 描述 |
|---|---|---|
| ida | - | 静态分析+动态调试 |
| gdb/gdb-peda | https://www.gnu.org/software/gdb/ | 动态调试工具 |
| pwntools | http://docs.pwntools.com/en/stable/ | 一个CTF框架和漏洞利用开发库 |
参考工具
这里列出来的工具是在某些情况下需要用到的工具,并不是像上面的工具一样随时都会用到(所以也只是简单的了解,并没有达到熟练运用的程度)。
| 工具名 | 链接 | 描述 |
|---|---|---|
| radare2 | https://github.com/radare/radare2 | 一个在linux平台(但不局限于此操作系统)下很好用的二进制逆向工具 |
| objdump | http://sourceware.org/binutils/docs-2.29/binutils/objdump.html | 用于二进制文件分析/可用于寻找gadgets,例如:查看可以利用的plt函数和函数对应的got表(objdump -d -j .plt 可执行文件名/objdump -R 可执行文件名) |
| readelf | https://github.com/radare/radare2 | 用于获取ELF文件的各种信息,例如:获取可执行文件level2的.bss段的地址readelf -S level2—— |
| ROPgadget | https://github.com/JonathanSalwan/ROPgadget | 用于寻找/构造二进制文件中的ROP链 |
| edb | https://github.com/eteran/edb-debugger | linux下的ollydbg |
| vim | https://www.vim.org/ | 从vi发展出来的一个文本编辑器 |
注:应用程序的plt表和got表
基础篇
这里列出的是各类pwn最核心的知识点。
栈溢出
栈溢出的特点就是通过溢出覆盖栈,来控制程序的执行流程:比如改变函数的指针,变量的值,异常处理程序,或者覆盖函数的返回地址,可以得到代码的执行权限。栈溢出的时候,会抛出一个访问违例;这样我们就能够在 fuzzing 的时候非常方便的跟踪到它们。
原理相关
- 程序的栈是从进程地址空间的高地址向低地址增长的,栈中的数据是先进后出
FILO—First-In/Last-Out的; - 函数调用栈的典型内存布局如下图所示——
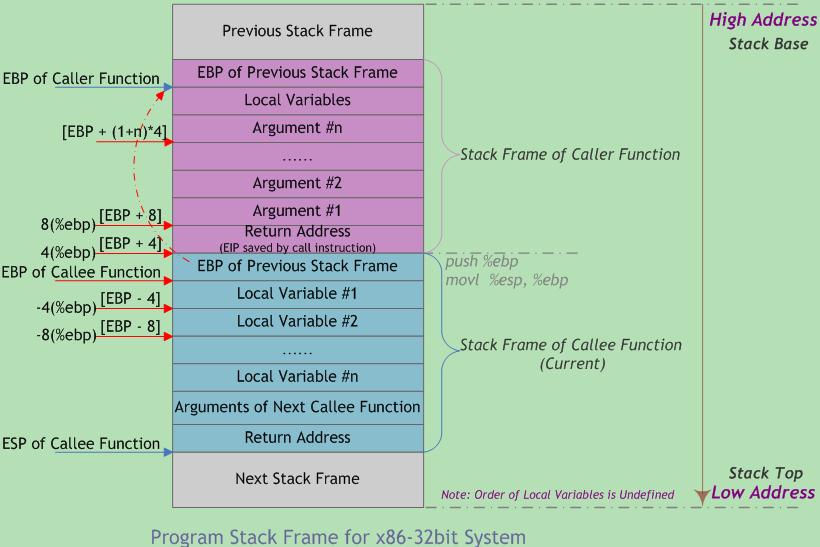
- 注意不同的函数调用约定对于分析和利用的影响;
函数调用约定:规定了函数参数的传递顺序和方式、栈的维护方式、名字修饰(Name-mangling)策略;
安全防护机制
数据执行保护(NX/DEP)、地址空间布局随机化(ALSR)、Stack Canary/ Cookie)及具体绕过方式的积累;注意不同的环境对于程序利用的影响:以x64和x86的主要区别为例——x86中参数都是保存在栈上,但在x64中的前六个参数依次保存在RDI,RSI,RDX,RCX,R8和 R9中,如果还有更多的参数的话才会保存在栈上;内存地址的范围由32位变成了64位。但是可以使用的内存地址不能大于0x00007fffffffffff,否则会抛出异常。
故linux_64不能像32位下那样通过报错寻找溢出点;
可通过查看报错后此时栈顶的数值从而知道PC被覆盖后要跳转的地址;
关键是利用相当于pop eip的ret指令。
一些常见汇编指令的含义积累。
相关寄存器的含义及理解(以x86的32位和64位为例,arm体系下用寄存器R0传递返回值)


- 函数参数的入栈顺序是自左往右的,好处如下图。

利用相关
栈溢出的基本利用是通过程序中的栈溢出,绕过各种防护机制,控制程序的执行流程,以达到控制程序执行其本身已有的代码(或我们填充进去的shellcode——要使shellcode所在内存地址所在段具有可执行权限)的目的。
最典型的栈溢出利用是首先覆盖程序的返回地址为攻击者所控制的地址,在此基础上,利用程序中已有的小片段
gadgets来改变某些寄存器或者变量的值,从而控制程序的执行流程或者传递所需函数参数。
gadgets——是以ret结尾的指令序列,通过这些指令序列,我们可以修改某些地址的内容,方便控制程序的执行流程;
- 栈溢出利用的几个关键。
- 积累常见危险函数,在程序中寻找确定栈溢出点;
- 结合程序开启的防护机制,确定利用思路及方式;
- 具体利用(包括画图构造具体栈分布、构造shellcode、确定填充长度、(非)通用gadgets的积累(获取)、构造ROP链等);
- 关注程序调用的动态链接库如libc.so,因为其中可能包含着大量可利用的函数;
- 一些关键指令的含义积累。
| 指令 | 等同于 |
|---|---|
| call func | push pc,jmp func |
| Leave | mov esp ebp,pop ebp |
| Ret | pop pc (相当于在栈顶弹出一个数据赋值给EIP寄存器) |
| push xxx | 将xxx压栈,将esp减4 |
| pop rdi | 弹栈,将此时esp所指内容存入rdi,同时esp加4 |
- 现代栈溢出利用技术基础——ROP:一种代码复用技术,通过控制栈调用来劫持控制流(一张图理解ROP原理);以及一些利用思路和技巧的积累。
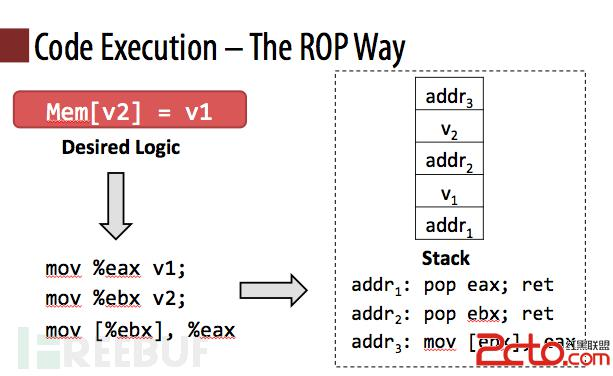
现代栈溢出利用技术基础:ROP
利用signal机制的ROP技术:SROP
没有binary怎么办:BROP 、dump bin
劫持栈指针:stack pivot
利用动态链接绕过ASLR:ret2dl resolve、fake linkmap
利用地址低12bit绕过ASLR:Partial Overwrite
绕过stack canary:改写指针与局部变量、leak canary、overwrite canary
溢出位数不够怎么办:覆盖ebp,Partial Overwrite
程序静态链接库文件时(只开启了NX保护):一种套路是可以通过程序中的静态链接函数mmap()和mprotect()来利用
......
- 利用pwntools编写利用脚本,简单示例如下图。
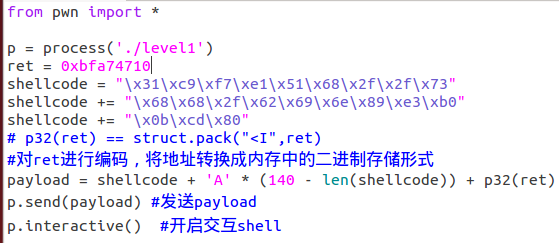
Shellcode指缓冲区溢出攻击中植入进程的恶意代码;
这段代码可以弹出一个消息框,也可以在目标机器上打开一个监听端口,甚至是删除目标机器上的重要文件等。
在实际场景中,我们通常使用Metasploit这个工具来定制各种功能的Shellcode;
当然也可以去网上查找一些现有的Shellcode进行测试,通常在shell-storm以及exploit-db等网站上都能找到一些比较成熟和稳定的shellcode.
- 利用过程中(静态分析+动态调试)的一些经验和技巧的积累。
参考资料
一步一步学ROP、ctf-wiki……
堆溢出
应用程序在运行的时候会动态的申请一块内存区域,这些区域就是堆。堆是一块一块连在一起的,负责存储元数据。当攻击者将数据覆盖到自己申请的堆以外的别的堆的时候,堆 溢出就发生了。接着攻击者能通过覆盖数据改变任何存储在堆上的数据:变量,函数指针,安全令牌,以及各种重要的数据。堆溢出很难被立即的跟踪到,因为被影响的内存快,一般 不会被程序立即的访问,需要等到程序结束之前的某个时间内才有可能访问到,当然也有可 能一直不访问。在 fuzzing 的时候我们就必须一直等到一个访问违例产生了才会知道,这个堆溢出是否在成功了。
原理相关
- 堆——对操作系统来说就是程序在运行时动态申请和释放的内存空间(malloc, realloc, free, new, del等);对数据结构来说:父亲总大于/小于儿子的特殊的完全二叉树;
- 不同操作系统对堆内存有不同的管理策略,某些软件(如浏览器)会自己实现堆内存管理;
- 利用堆漏洞的关键-了解内存管理的策略;
- 一些相关的基础知识:Glibc Heap简介
CTF题中堆管理机制:大多数是ptmalloc/dlmalloc, 少数题中自己实现;
- 对于堆溢出漏洞,重点关注malloc()相关函数(如果有malloc任意size的代码就很有可能可以被利用);同时需要关注函数里面存在的结构体及结构体中包含的具体内容的类型(注意有无指针这种利用度高的数据类型)——结构体示例如图所示。
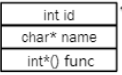
- 关于chunk——chunk的大小在32位系统下最小16 bytes,对齐8 bytes;64位系统下最小32 bytes,对齐16 bytes;
如果malloc的size没有16字节对齐,比如malloc(0x18),系统实际malloc了0x20字节给程序;
因为对齐的缘故,size的低3位用于记录chunk的一些flag;

将传入malloc的size加上8 bytes的overhead并向16 bytes对齐,如果不足32 bytes则分配32 bytes,之后所有分配用的size都用调整后的;
chunk的具体结构如图;

- 关于bins;


- 关于malloc chunk的分配策略——

- 关于main_arena:其中存放的内容与bins相关;



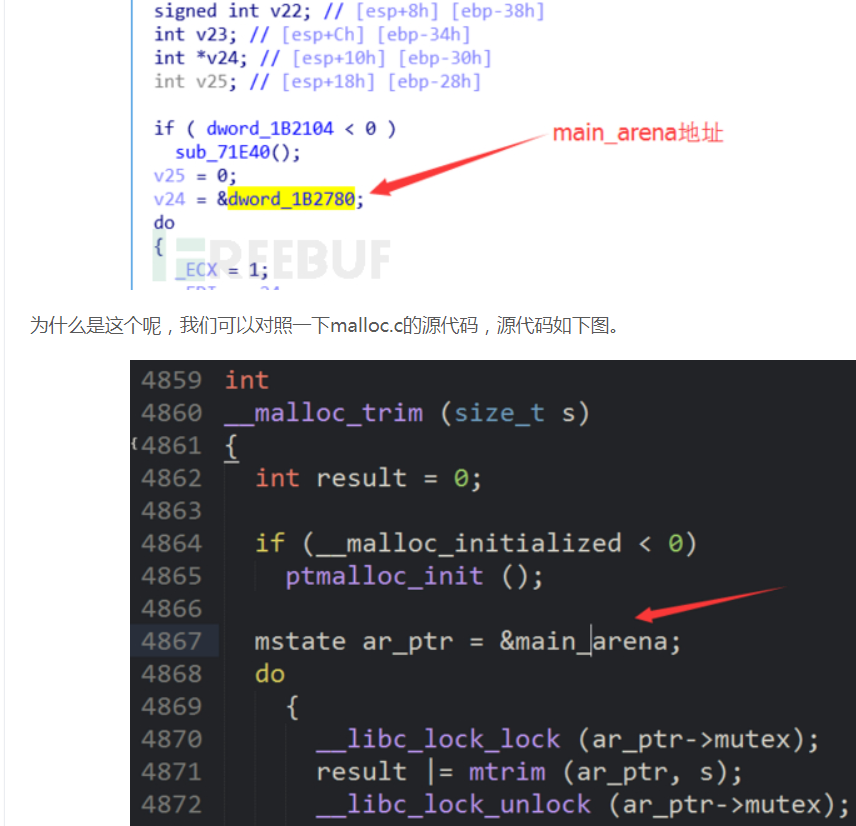
利用相关
各种利用方式积累如——
UAF:判断程序是否存在UAF漏洞——程序创建的结构体中是否包含指针变量,并且在free了创建的结构体chunk(堆)之后没有将其中的指针置为null/0。如实例1所示。



实例1——


Double Free:双重释放漏洞主要是由对同一块内存进行二次重复释放导致的,利用漏洞可以执行任意代码,如实例2所示。
实例2——


unlink、fastbin attack、unsorted bin attack、off-by-one、house of force等House of Force——攻击者利用这个漏洞可以实现控制下一个chunk的地址以及任意地址写。https://github.com/ctf-wiki/ctf-wiki/blob/master/docs/pwn/linux/glibc-heap/house_of_force.md
https://gbmaster.wordpress.com/2014/08/11/x86-exploitation-101-heap-overflows-unlink-me-would-you-please/unlink——具体的利用方式描述如下;


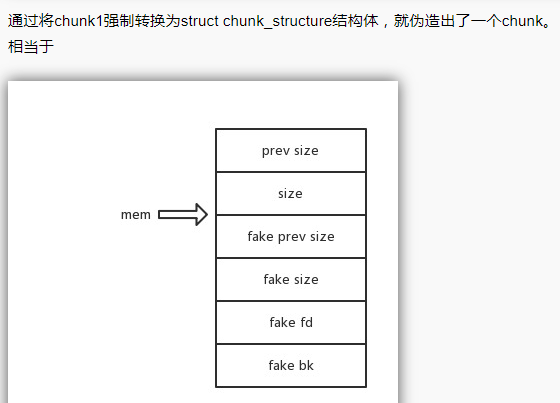
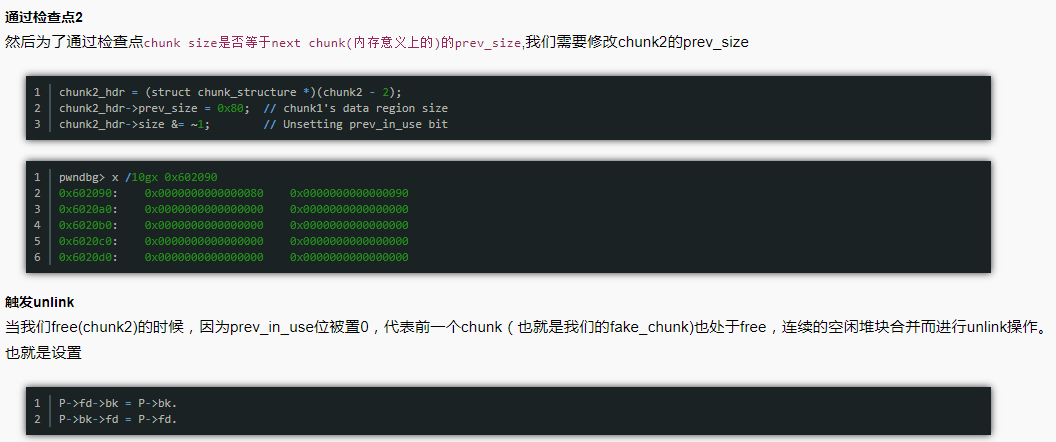
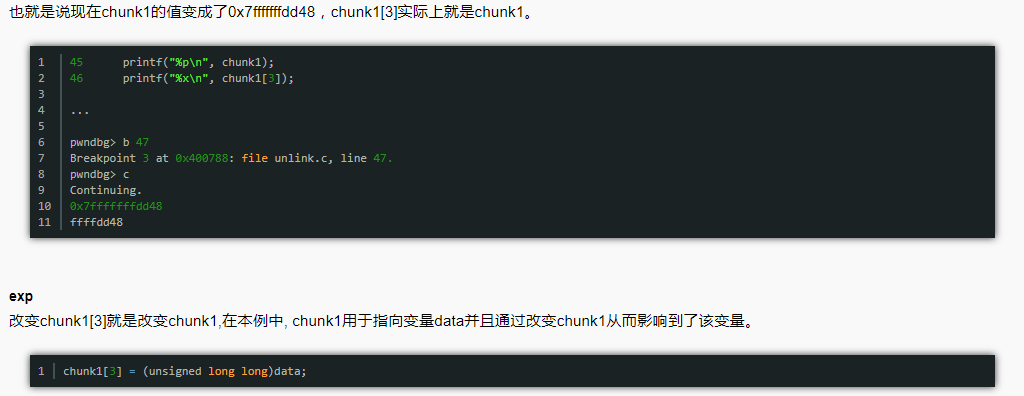
Extend the chunk+ off by one;

参考资料
Glibc内存管理Ptmalloc2源代码分析……
其他
格式化字符串漏洞
原理相关
- 会触发该漏洞的函数很有限,主要就是printf、sprintf、fprintf等print家族函数。
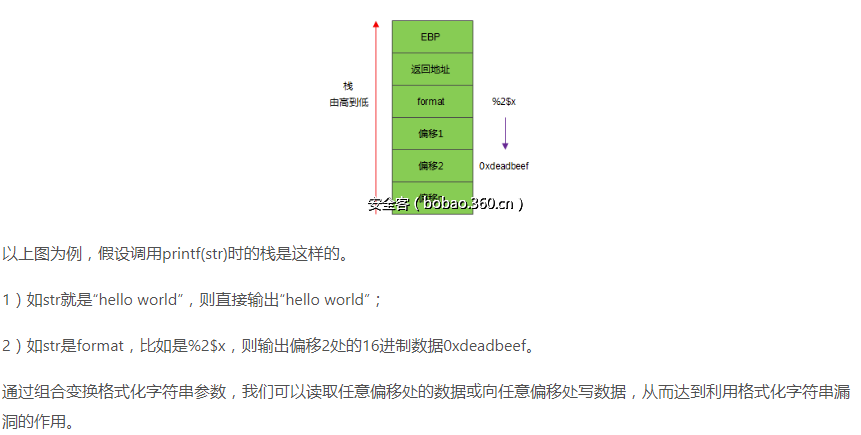
- 需要了解基本的格式化字符串参数;重点关注的是%s(实现任意地址读)、%x和%n(实现任意地址写)、%p(判断可执行文件是否存在格式化字符串漏洞以及爆破偏移)。

利用相关
- 对于一些没有给二进制文件的ctf题目,可以输入%p等检测其是否具有格式化字符串漏洞,若有可将其二进制bin文件泄露出来。
- 若漏洞点不在栈上,而是其他位置如堆、.bss段,此种情况下无法很好的控制栈上的数据,该如何利用?参考题目见lab9。
整数溢出漏洞
原理相关
- 程序在处理(编译器标准的)有符号整数过程中存在的问题;
- 一个有符号整数,由 2 个字节组成,表示的范围从 -32767 到 32767;
- 当我们从尝试向存储一个整数的地方写入超过其大小的数字的时候,整数溢出就触发了;
- 因为存入的数字太大,处理器会自动的将高位多出来的字节丢弃;
利用相关
我们通过一个设计好的例子来理解。
MOV EAX, [ESP + 0x8]
LEA EDI, [EAX + 0x24]
PUSH EDI
CALL msvcrt.malloc
假设在栈中的数据是一个有符号整数,而且非常大,几乎接近了有符号整数的最大值32767,然后传递给 EAX,EAX 加上 0x24,整数溢出,最后我 们得到一个非常小的值,如下所示。
Stack Parameter => 0xFFFFFFF5
Arithmetic Operation => 0xFFFFFFF5 + 0x24
Arithmetic Result => 0x100000019 (larger than 32 bits)
Processor Truncates => 0x00000019
如果一切顺利,malloc将只申请 0x19 个字节大小的空间,这块内存比程序本身要申请的空间小很多。如果程序将一大块的数据写入这块区域,缓冲区溢出就发生了。
题目篇
对于实践过程中出现的各种漏洞函数以及利用方式的整理和积累。
栈溢出
| 漏洞函数/漏洞点 | 触发原因 | 补充说明 | 参考题目 |
|---|---|---|---|
memcpy |
size过大,导致可以覆盖dest/栈上内容如返回地址 | … | 湖湘杯Pwn、R0pbaby、fuckzing-exploit-200 |
gets |
gets从标准输入设备读字符串函数,其可以无限读取,不会判断上限,以回车结束读取 | ||
jle——如图1 |
jle为有符号比较, 我们可以通过使用负数绕过该判断, 从而覆盖栈 | ||
数组赋值操作——如图2 |
base64解码的结果存入char数组v21[257],base64解码之后的数据大小大概是原来512的3/4,造成栈溢出 |
… | 湖湘杯Pwn |
scanf——如代码1 |
读了一个24位的字符串,覆盖到了一个整型的地址上;若此处改为__isoc99_scanf("%24s", &v7)则并未造成栈溢出 |
但是溢出长度较小,不够填充shellcode,所以需要结合其他漏洞进行利用 | echo1 |
自定义函数get_input——如代码1 |
s的length为32,但是输入确有128个字节 | 填充shellcode,覆盖返回地址(直接覆盖为shellcode的地址;或利用跳板jmp esp-多适用于ret地址后面紧跟shellcode的情况) |
echo1 |
自定义函数sub_400330((__int64)&v2, a1, 80LL)——如代码2 |
在该函数中,sub_400330拷贝80个字节到v2 ebp-0x40处的位置,此处v2所指向的buf的大小为0x40h,造成栈溢出,但此时的溢出长度较小不够填充shellcode,只能用于劫持程序控制流 | 此时需要利用stack pivot 劫持esp到攻击者控制的区域如.bss,从而可以有足够的空间做ROP |
vss |
read——如图3 |
buf大小为0x88(136)字节,而read最多可以读入0x100(256)字节 | 题目给了libc,考虑ret2libc | ropasaurusrex、pwnme、baby stack、task_gettingStart |
strcpy |
该函数没有检查数据长度 | … | lab4 |
图1——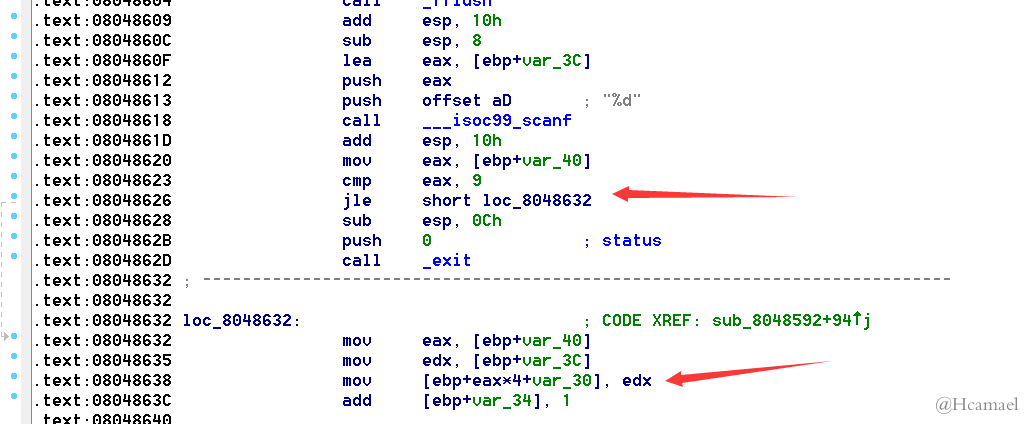
图2——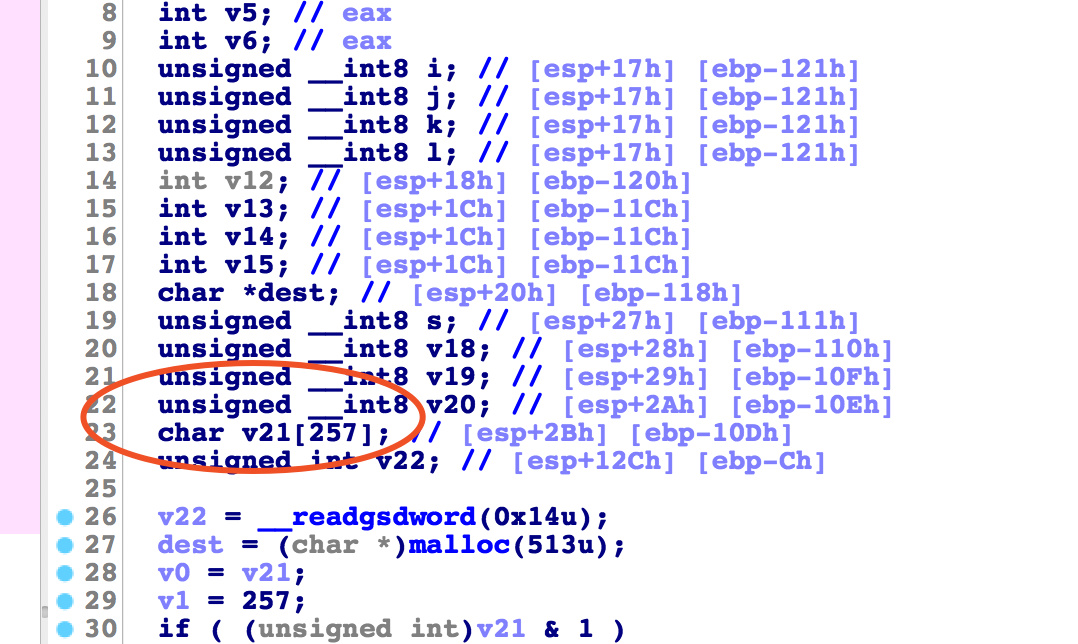
代码1——
int echo1()
{
char s; // [sp+0h] [bp-20h]@1
(*((void (__fastcall **)(_QWORD))o + 3))(o);
get_input(&s, 128);
puts(&s); //漏洞点1
(*((void (__fastcall **)(_QWORD, _QWORD))o + 4))(o, 128LL);
return 0;
}
int main(int argc, const char **argv, const char **envp)
{
int *v3; // rsi@1
_QWORD *v4; // rax@1
int v6; // [sp+Ch] [bp-24h]@1
_QWORD v7[4]; // [sp+10h] [bp-20h]@1
setvbuf(stdout, 0LL, 2, 0LL);
setvbuf(stdin, 0LL, 1, 0LL);
o = malloc('(');
*((_QWORD *)o + 3) = greetings;
*((_QWORD *)o + 4) = byebye;
printf("hey, what's your name? : ", 0);
v3 = (int *)v7;
__isoc99_scanf("%24s", v7); //漏洞点2
v4 = o;
*(_QWORD *)o = v7[0];
v4[1] = v7[1];
v4[2] = v7[2];
id = v7[0];
......
代码2——
signed __int64 __fastcall sub_40108E(__int64 a1)
{
signed __int64 result; // rax@3
int v2; // [sp+10h] [bp-40h]@1
__int64 v3; // [sp+20h] [bp-30h]@1
__int64 v4; // [sp+28h] [bp-28h]@1
__int64 v5; // [sp+30h] [bp-20h]@1
__int64 v6; // [sp+38h] [bp-18h]@1
__int64 v7; // [sp+40h] [bp-10h]@1
unsigned int v8; // [sp+48h] [bp-8h]@7
int v9; // [sp+4Ch] [bp-4h]@4
v3 = 0LL;
v4 = 0LL;
v5 = 0LL;
v6 = 0LL;
v7 = 0LL;
v2 = 0;
sub_400330((__int64)&v2, a1, 80LL);//栈溢出
if ( (_BYTE)v2 != 'p' || BYTE1(v2) != 'y' )//判断payload的前两位是否是'py'
{
v9 = sub_419550(&v2);
for ( dword_6C7A98 = 0; dword_6C7A98 < v9; ++dword_6C7A98 )
*((_BYTE *)&v2 + dword_6C7A98) ^= 0x66u;
v8 = sub_437E40("pass.enc", 0LL);
if ( v8 == -1 )
sub_407700(0xFFFFFFFFLL);
sub_437EA0(v8, &v3, 40LL);
result = sub_400360(&v2, &v3) == 0;
}
......
图3——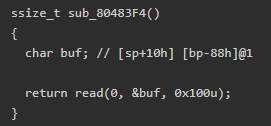
关于如何通过形如
char buf; // [sp+10h] [bp-88h]@1的ida伪码中看出buf的大小;buf的大小为0x88h;
可能的解释:在堆栈中变量分布是从高地址到低地址分布,EBP是指向栈底(高地址)的指针,在过程调用中不变,又称为帧指针。ESP指向栈顶(低地址),程序执行时移动,ESP减小分配空间,ESP增大释放空间,ESP又称为栈指针;
可能的解释续:在汇编代码中可以看出,由于ebp的值的稳定性,所以对于变量的定位多是用形如[ebp-xxh]这样的偏移来进行的,故可能这个相对于ebp的偏移地址就是变量所占的内存空间的大小;
堆溢出
| 漏洞函数/漏洞点 | 触发原因 | 补充说明 | 参考题目 |
|---|---|---|---|
delete(C++中定义的关键字)——如图1 |
UAF | delete——new/delete、new[]/delete[] 要配套使用,对于内置类型的对象,用 new [] 来创建类对象数组,而用 delete 来释放,如果类对象中申请了大量的内存需要在析构函数中释放,而你却在销毁数组对象时少调用了析构函数,这会造成内存泄漏 | UAF |
free |
UAF | 如果在free某个chunk之后没有将其中存在的指针置为0/null,则可能会导致UAF | lab10 |
read |
read的长度是由用户输入指定的,这里就可能存在一个溢出点 | … | lab11 |
图1——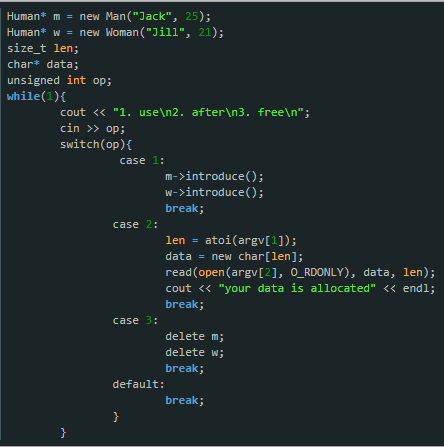
其他
| 漏洞函数/漏洞点 | 触发原因 | 补充说明 | 参考题目 |
|---|---|---|---|
scanf——如图1 |
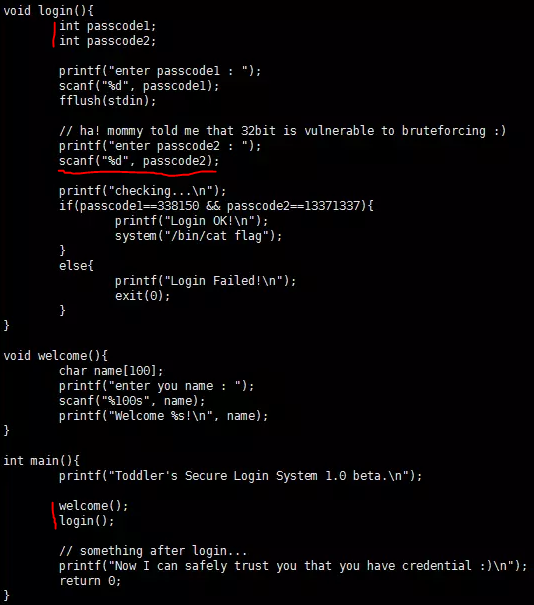
1)在 login 函数调用 scanf 的时候,对参数没有取址的操作,即 scanf 把数据保存到 passcode1中的值指向的那个地址里; 2)main 函数连续调用 welcome 和 login 函数,并且二者的参数个数相同均为0,可能会导致二者的基地址ebp是相同的—动态调试验证,从而导致 welcome 函数的变量的值可能影响 login 函数中的具体变量值 | 如果此时能控制passcode1的值,即可实现任意地址写 | password |
strstr |
可通过字符串拼接等方式绕过此函数验证 | … | cmd1 |
print |
使用函数时未指定格式化字符,如print(&buf) 或 print(buf) |
… | lab7/lab9、lab8 |
图1——