对AFL的实现原理的学习笔记。
学习1
关键:AFL通过实现对已有编译器的扩展实现在程序编译时的插桩操作;
学习2
https://stfpeak.github.io/2017/06/11/Finding-bugs-using-AFL/
https://stfpeak.github.io/2017/06/12/AFL-Cautions/
关键:
有大牛表示:“AFL Fuzzing without ASAN is just a waste of CPU”。
ASAN——Linux下内存检测工具;ASAN(Address-Sanitizier)早先是LLVM中的特性,后被加入GCC 4.8,在GCC 4.9后加入对ARM平台的支持。因此GCC 4.8以上版本使用ASAN时不需要安装第三方库,通过在编译时指定编译CFLAGS即可打开开关。
在开启ASAN后。afl插桩则会在目标代码的关键位置添加检查代码,例如:malloc(),free()等,一旦发现了内存访问错误,便可以SIGABRT中止程序。
例如越界读等内存访问错误不一定会造成程序的崩溃,所以在没有开启ASAN的情况下,许多内存漏洞都无法被AFL给发现。所以在编译二进制代码的时候,强烈建议开启ASAN。
ASAN开启后的fuzzing会消耗更多的内存,这是需要注意的因素,对于32位的程序,基本上800MB即可;但64为程序大概需要20TB,所以,使用ASAN的话,建议添加CFLAGS=-m32来限制编译目标为32位,否则,可能应为64位消耗内存过多而造成程序崩溃。
在使用了ASAN之后,可以再alf-fuzz的时候通过选项-m来指定使用的内存上限。启用了ASAN的32位程序,一般设置-m 1024即可。
- 在无源码的情况下Fuzzing二进制文件,详细请参见afl/qemu_mode/README.qemu。
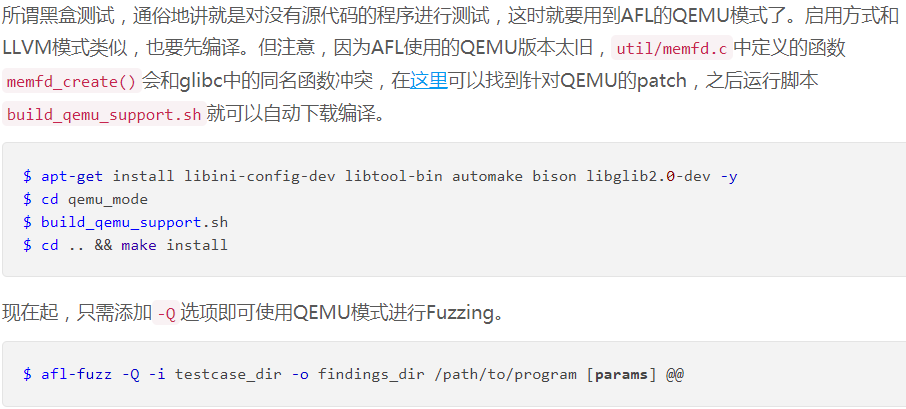
QEMU使用基本块作为翻译单元;插桩(伪码如下)在此基础上实现,并使用一个与编译时hooks类似的模型
if (block_address > elf_text_start && block_address < elf_text_end) {
cur_location = (block_address >> 4) ^ (block_address << 8); //消减指令对齐的影响
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
- 像QEMU、DynamoRIO和PIN这样的二进制翻译的启动是相当缓慢的;为了解决这个问题,QEMU模式利用了一个类似于编译时插装的fork服务器,在开始时暂停然后有效地生成已经初始化的进程的副本。
学习3
https://blog.csdn.net/gengzhikui1992/article/details/50844857(原理解析)
关键:
插桩、代码覆盖率的计算、新的程序执行路径的发现、Fuzzing策略、Crash的去重、the fork server;
黑盒二进制目标程序的上述功能的实现。
学习4
https://blog.csdn.net/qq_32464719/article/details/80592902——AFL技术实现分析(源码解析,详细、清晰)
关键:
AFL的代码插桩,就是在将源文件编译为汇编代码后,通过afl-as完成(afl-as.c)。
在处理到某个分支,需要插入桩代码时,afl-as会生成一个随机数,作为运行时保存在ecx中的值。而这个随机数,便是用于标识这个代码块的key;
在分支点注入的代码本质上相当于——, 这里显示的是执行的伪代码,我们回到_afl_maybe_log()中,可以看到执行代码;
cur_location = ; shared_mem[cur_location ^ prev_location]++; prev_location = cur_location >> 1;
- 在每个插桩处,afl-as会添加相应指令,将ecx的值设为0到MAP_SIZE之间的某个随机数,从而实现了伪代码中的
cur_location = <COMPILE_TIME_RANDOM>;
- 因此,AFL为每个代码块生成一个随机数,作为其“位置”的记录;随后,对分支处的”源位置“和”目标位置“进行异或,并将异或的结果作为该分支的key,保存每个分支的执行次数。这个 cur_location的值随机产生来简化对于复杂程序的链接过程而且还要保持XOR输出的均匀分布。
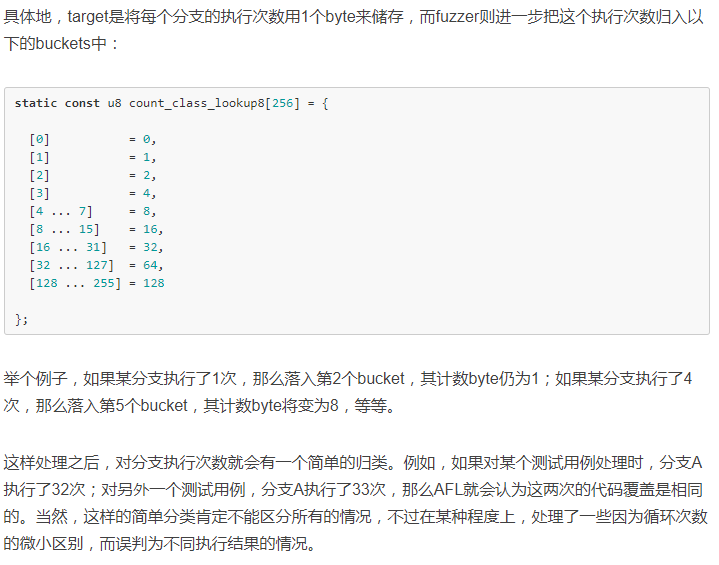
AFL会用一片大小为64KB的共享内存来存储二进制程序的信息。在输出的map中的每一个Byte字节用来保存被插装程序中的 (branch_src, branch_dst)命中信息。
因为保存执行次数的实际是一张哈希表所以会存在碰撞问题。我们选择MAP_SIZE=64K,这其中可以保存大约 2k 到 10k程序分支点。对于不是很复杂的程序程序的碰撞还是可以接受的;
这种形式的覆盖提供了比简单的块覆盖更深入地了解程序的执行路径。特别地,它将以下执行跟踪区分开来: 这有助于在底层代码中发现微妙的错误条件,因为安全漏洞通常与意外或不正确的状态转换相关联,而不仅仅是到达一个新的基本块。
A -> B -> C -> D -> E (tuples: AB, BC, CD, DE)
A -> B -> D -> C -> E (tuples: AB, BD, DC, CE)
3)中移位操作的原因在伪代码的最后一行显示在本节的方向性保护tuples,假设target中存在A->A和B->B这样两个跳转,如果不右移,那么这两个分支对应的异或后的key都是0,从而无法区分;另一个例子是A->B和B->A,如果不右移,这两个分支对应的异或后的key也是相同的。
下面所示的第二个跟踪将被认为是全新的,因为存在新的tuples(CA,AE):
1: A -> B -> C -> D -> E 2: A -> B -> C -> A -> E
同时,因为#2的出现下面的路径将不会被认为是一条独特的路径,尽管有一个明显不同的总体执行路径:
3: A -> B -> C -> A -> B -> C -> A -> B -> C -> D -> E
思考:这种策略虽然会提高执行效率,但也有可能会漏掉一些可能会产生新的路径覆盖的样本数据,考虑能否在判断代码覆盖率的过程中增加对于整个总体执行路径的考虑?
总的来讲,AFL维护了一个队列(queue),每次从这个队列中取出一个文件,对其进行大量变异,并检查运行后是否会引起目标崩溃、发现新路径等结果。变异的主要类型如下:
bitflip,按位翻转,1变为0,0变为1 arithmetic,整数加/减算术运算 interest,把一些特殊内容(AFL预设的一些比较特殊的数,基本都是可能会造成溢出的数)替换到原文件中 dictionary,把自动生成或用户提供的token替换/插入到原文件中 havoc,中文意思是“大破坏”,此阶段会对原文件进行大量变异,具体见下文 splice,中文意思是“绞接”,此阶段会将两个文件拼接起来得到一个新的文件
其中,前四项bitflip, arithmetic, interest, dictionary是非dumb mode(-d)和主fuzzer(-M)会进行的操作,由于其变异方式没有随机性,所以也称为deterministic fuzzing;havoc和splice则存在随机性,是所有状况的fuzzer(是否dumb mode、主从fuzzer)都会执行的变异
关于effector map:具体地,在对每个byte进行翻转时,如果其造成执行路径与原始路径不一致,就将该byte在effector map中标记为1,即“有效”的,否则标记为0,即“无效”的。 这样做的逻辑是:如果一个byte完全翻转,都无法带来执行路径的变化,那么这个byte很有可能是属于”data”,而非”metadata”(例如size, flag等),对整个fuzzing的意义不大。所以,在随后的一些变异中,会参考effector map,跳过那些“无效”的byte,从而节省了执行资源。 由此,通过极小的开销(没有增加额外的执行次数),AFL又一次对文件格式进行了启发式的判断。
如果满足以下两个条件中的任何一个,afl-fuzz中实现的解决方案将认为崩溃是唯一的:
crash trace中包含一个在以前的崩溃中没有看到的tuples; crash trace中缺少一个在早期错误中总是存在的tuples。
学习5
http://rk700.github.io/2017/12/28/afl-internals/(源码解析,详细、清晰)
关键:
编译target完成后,就可以通过afl-fuzz开始fuzzing了。其大致思路是,对输入的seed文件不断地变化,并将这些mutated input喂给target执行,检查是否会造成崩溃。因此,fuzzing涉及到大量的fork和执行target的过程。
为了更高效地进行上述过程,AFL实现了一套fork server机制。其基本思路是:启动target进程后,target会运行一个fork server;fuzzer并不负责fork子进程,而是与这个fork server通信,并由fork server来完成fork及继续执行目标的操作。这样设计的最大好处,就是不需要调用execve(),从而节省了载入目标文件和库、解析符号地址等重复性工作。如果熟悉Android的话,可以将fork server类比为zygote。
参考资料
https://blog.csdn.net/qq_32464719/article/details/80277603
https://zhuanlan.zhihu.com/p/51443698
http://0x4c43.cn/2018/0722/use-afl-for-fuzz-testing/
http://www.voidcn.com/article/p-avxtnarw-bpk.html
https://www.freebuf.com/articles/system/191536.html
https://github.com/mirrorer/afl/blob/master/qemu_mode/README.qemu
https://github.com/mirrorer/afl/tree/master/docs
https://bbs.pediy.com/thread-249912.htm
……