对于《C++反汇编揭秘》第四章的Crackme的分析尝试。
一、自己尝试分析
最初自己尝试分析如下——
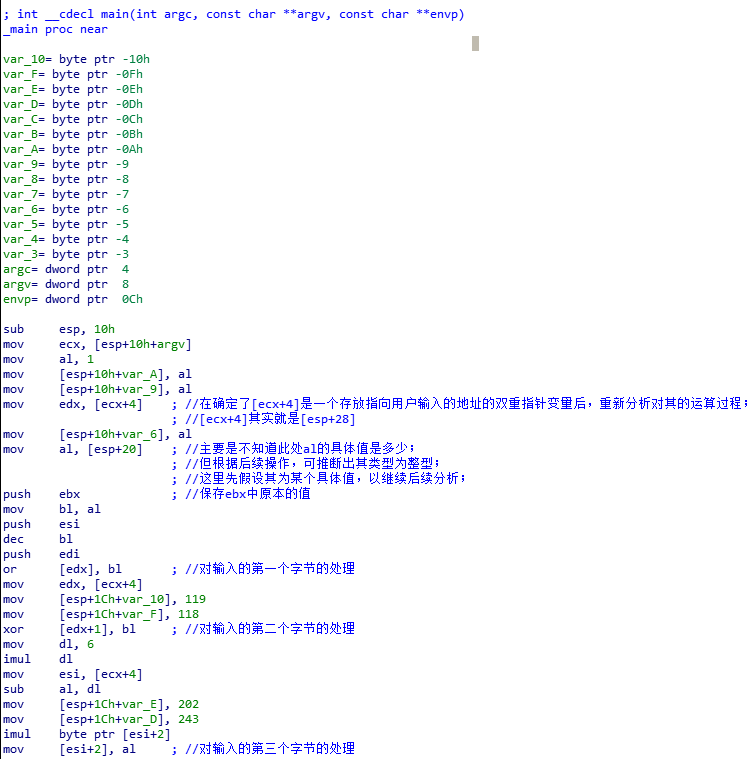

最开始有点晕,因为不熟悉类似于[esp+10h+var_A]和[esp+1Ch+var_E]之类的变量寻址,所以对于一些初始值并不清楚是怎样的关系,并未具体分析每个字节的处理。后来在看教材上的分析时跟着分析了各个字节的具体处理,并在对比总结部分中列出了最开始理解起来比较困难的地方。
二、教材上的分析
1.程序分析片段1——

2.程序分析片段2——




3.程序分析片段3——



4.源码还原——
由于加密中大部分的位运算都是不可逆的,所以这里无法通过加密后的字符串反推出正确的字符串,教材中给出了该程序的正确密码:”www.51asm.com“。

三、对比总结
通过学习教材上的分析,总结出自己分析过程中不足的知识点如下——
1.对于函数局部变量偏移的理解以及在ida中识别数组;

2.对于类似于[esp+10h+var_A]和[esp+1Ch+var_E]之类的变量寻址的理解;
对于这种形式的寻址,我们可以将其转换为更容易理解的基于ebp的寻址形式。
sub esp, 10h //在此操作之前,esp和ebp的值是一样的;
//经过此操作后,esp=ebp-10h,也即是ebp=esp+10h;
mov ecx, [esp+10h+argv] //所以[esp+10h+argv]=[ebp+argv],所以这里存入ecx的就是main函数的参数argv;
mov al, 1
mov [esp+10h+var_A], al //[esp+10h+var_A]=[ebp+var_A]=[ebp-Ah],局部变量赋值操作;
mov [esp+10h+var_9], al
mov edx, [ecx+4] //[ecx+4]=[ebp+argv+4],即取出argv[1];
mov [esp+10h+var_6], al
mov al, byte ptr [esp+10h+argc] //[esp+10h+argc]=[ebp+argc],即al=argc;
push ebx //保存ebx中原本的值,esp-4;
mov bl, al
push esi //esp-4;
dec bl
push edi //esp-4;
or [edx], bl
mov edx, [ecx+4]
mov [esp+1Ch+var_10], 119 //到此时,ebp=esp+1ch,所以[esp+1Ch+var_10]=[ebp+var_10];
mov [esp+1Ch+var_F], 118
...
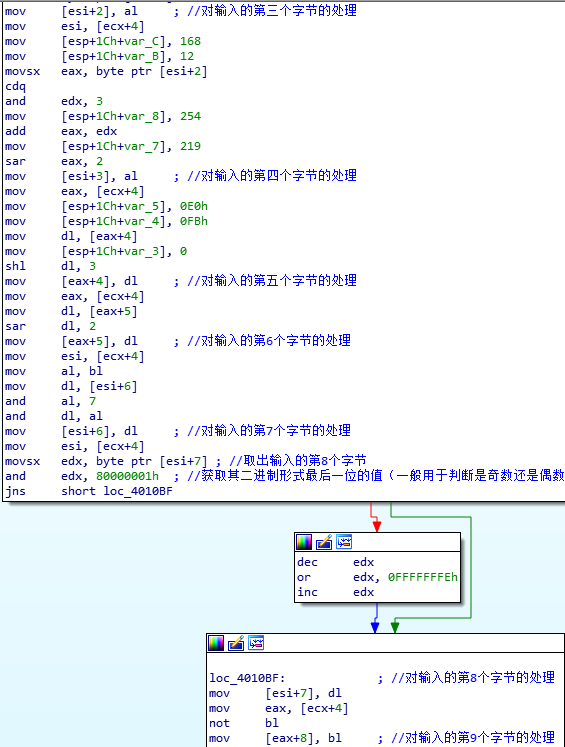
3.对于第四个字节的”/4”的除法处理的理解;
mov esi, [ecx+4]
mov [esp+1Ch+var_C], 168
mov [esp+1Ch+var_B], 12
movsx eax, byte ptr [esi+2]
cdq
and edx, 3
mov [esp+1Ch+var_8], 254
add eax, edx
mov [esp+1Ch+var_7], 219
sar eax, 2
mov [esi+3], al
对于上述代码的理解可以参考下图——

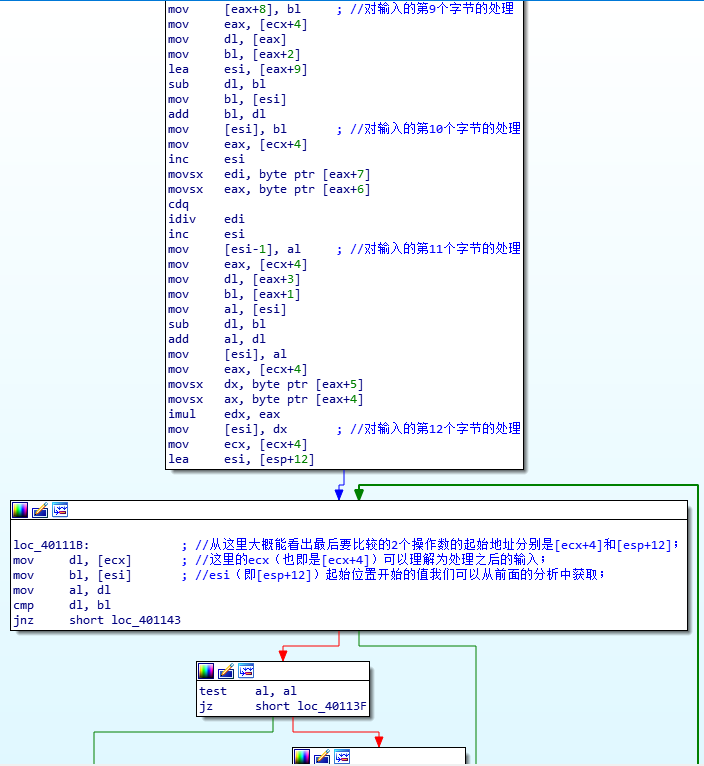
4.对于第八个字节的取模运算的理解;
movsx edx, byte ptr [esi+7] //取出输入的第8个字节
and edx, 80000001h
jns short loc_4010BF
dec edx
or edx, 0FFFFFFFEh
inc edx
loc_4010BF:
mov [esi+7], dl
对于上述代码的理解可以参考下图——

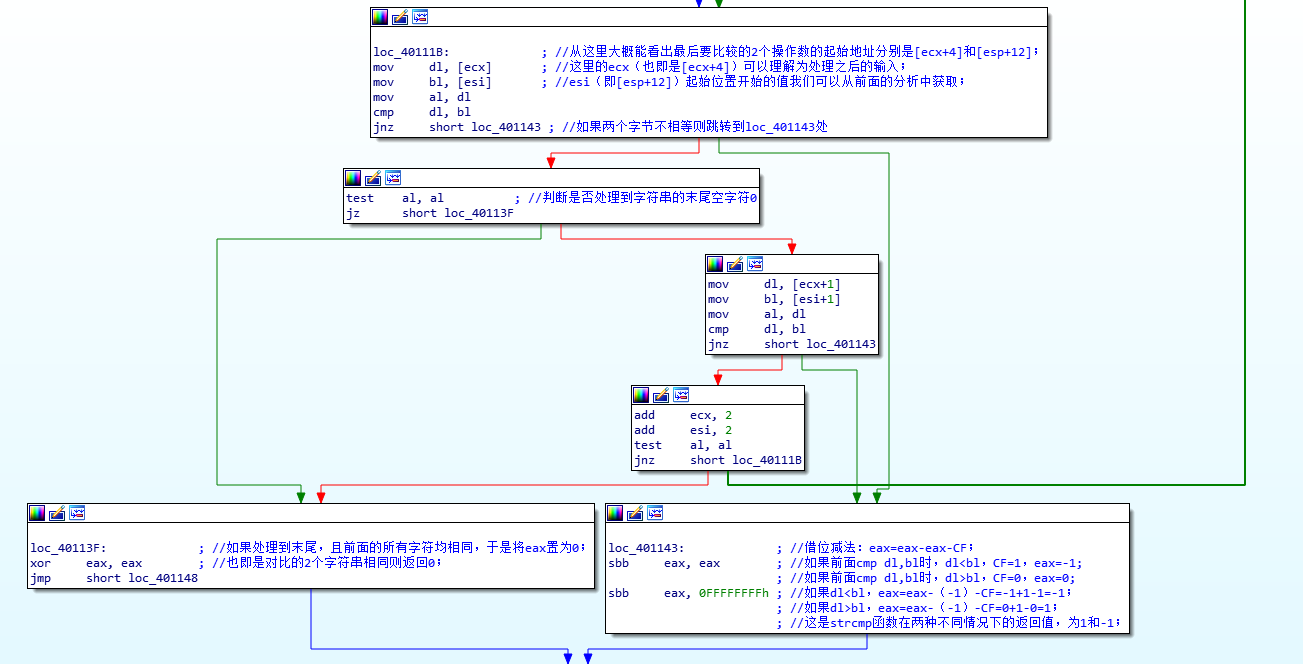
5.strcmp函数的汇编实现的理解;
补充知识1——CMP指令对于标志位CF,ZF,OF,SF的影响;

补充知识2——关于strcmp函数;
int strcmp(char *s1,char *s2)
{
for(int i=0;s1[i]!='\0'||s2[i]!='\0';i++)
if(s2[i]=='\0'||s1[i]>s2[i])return 1; //串s1已经结束或者相同位置上的字符大于s2
else if(s1[i]=='\0'||s1[i]<s2[i])return -1; //串s2已经结束或者相同位置上的字符大于s1
return 0; //s1等于s2
}
对于汇编的分析理解如下图——