对于《逆向工程实战》的2.12节练习的尝试(ARM)。
一、基础知识补充
1.相关指令积累
- 无符号数长乘指令
UMULL——UMULL{条件}{S} 目的寄存器Low,目的寄存器低High,操作数1,操作数2
UMULL 指令完成将操作数1 与操作数2 的乘法运算,并把结果的低32 位放置到目的寄存器Low 中,结果的高32 位放置到目的寄存器High 中,同时可以根据运算结果设置CPSR 中相应的条件标志位。其中,操作数1 和操作数2 均为32 位的无符号数。举例如下:
UMULL R0,R1,R2,R3 //R0 = (R2 × R3)的低32 位;R1 = (R2 × R3)的高32 位
//UMULL指令实现64bit无符号数乘法
- 条件跳转指令
BMI——BMI offeset
若应用程序状态寄存器APSR中的标志位N(负值标志位)的值为1,表明运算的结果是负数,则跳转到offeset处。
SUBS R7,R7,#0x30
BMI loc_B318 //如果SUBS的计算结果为负数,则跳转到loc_B318处
- 乘-累加指令
MLA——MLA{条件}{S} 目的寄存器,操作数1,操作数2,操作数3
MLA 指令完成将操作数1 与操作数2 的乘法运算,再将乘积加上操作数3,并把结果放置到目的寄存器中,同时可以根据运算结果设置CPSR中相应的条件标志位。其中,操作数1 和操作数2 均为32 位的有符号数或无符号数。
MLA R0,R1,R2,R3 //R0 = R1 × R2 + R3
MLAS R0,R1,R2,R3 //R0 = R1 × R2 + R3,同时设置CPSR 中的相关条件标志位
- 带进位减法指令
SBC——SBC{条件}{S} 目的寄存器,操作数1,操作数2
SBC 指令用于把操作数1 减去操作数2,再减去CPSR 中的C 条件标志位的反码,并将结果存放到目的寄存器中。操作数1 应是一个寄存器,操作数2 可以是一个寄存器,被移位的寄存器,或一个立即数。该指令使用进位标志来表示借位,这样就可以做大于32 位的减法,注意不要忘记设置S 后缀来更改进位标志。该指令可用于有符号数或无符号数的减法运算。
SUBS R0, R3, R6 //减最低位字节,不带进位
SBCS R1, R4, R7 //减第二个字,带进位
SBCS R2, R5, R8 //减第三个字,带进位
//三句话实现了96bit减法运算,由于ARM寄存器宽度只有32bit所以分三次相减
- 算术右移操作
ASR(高位用第31位的值填充)——通用寄存器,ASR 操作数
ASR 可完成对通用寄存器中的内容进行右移的操作,按操作数所指定的数量向右移位,左端用第31 位的值来填充。其中,操作数可以是通用寄存器,也可以是立即数(0~31)。
MOV R0, R1, ASR #2 //将R1 中的内容右移两位后传送到R0 中,左端用第31 位的值来填充。
- 不带进位逆向减法指令
RSB——RSB{条件}{S} 目的寄存器,操作数1,操作数2
RSB指令称为逆向减法指令,用于把操作数2 减去操作数1,并将结果存放到目的寄存器中。操作数1 应是一个寄存器,操作数2 可以是一个寄存器,被移位的寄存器,或一个立即数。该指令可用于有符号数或无符号数的减法运算。
RSB R0, R1, R2 //R0 = R2- R1
RSB R0, R1, #112 //R0 = 112- R1
RSB R0, R1, R2, LSL#1 //R0 = (R2<<1)-R1
- 比较跳转指令
CBZ和CBNZ——CBZ Rn, label和CBNZ Rn, label
Rn 是存放操作数的寄存器。label 是跳转目标。用法:可以使用 CBZ 或 CBNZ 指令避免更改条件代码标记并减少指令数目。
除了不更改条件代码标记外,CBZ Rn, label 与下列指令序列功能相同:
CMP Rn, #0
BEQ label
除了不更改条件代码标记外,CBNZ Rn, label 与下列指令序列功能相同:
CMP Rn, #0
BNE label
补充说明——
- 跳转目标必须在指令之后的 4 到 130 个字节之内。
- 这些指令一定不能在 IT 块内使用。
- 这些指令不更改标记。
- 这些 16 位 Thumb 指令可用于 ARMv6T2 及更高版本。
- 这些指令没有 ARM 或 32 位 Thumb 版本。
- 不带进位减法
SUB——SUB{条件}{S} 目的寄存器,操作数1,操作数2
SUB 指令用于把操作数1 减去操作数2,并将结果存放到目的寄存器中。操作数1 应是一个寄存器,操作数2 可以是一个寄存器,被移位的寄存器,或一个立即数。该指令可用于有符号数或无符号数的减法运算。
SUB R0,R1,R2 //R0 = R1 - R2
SUB R0,R1,#256 //R0 = R1 - 256
SUB R0,R2,R3,LSL#1 //R0 = R2 - (R3 << 1)
SUBS R0, #1 //R0自减1
参考资料如下——
(1)CBZ和CBNZ指令使用说明《realview编译工具》;
(2)常用的arm汇编指令(2);
(3)ARM指令集详解;
二、练习题
补充说明:针对下面每个题目中的代码,尽可能的按顺序进行如下练习:

题目(1)
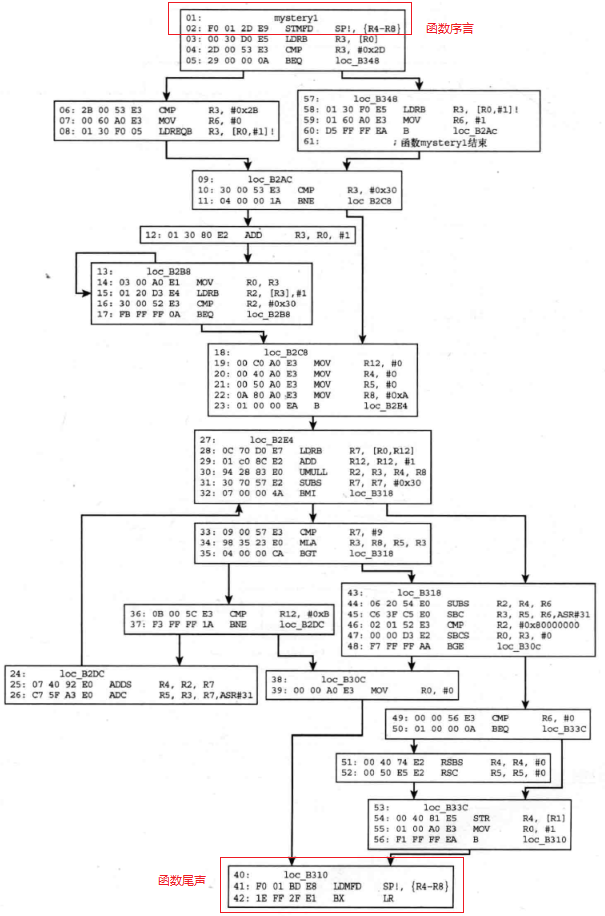
解答如下——
- 代码是运行于ARM状态,可根据4字节的指令长度以及函数序言/尾声(如图中红框框起来的部分所示)中的入栈/出栈操作判断得到。
接下来对函数的各个汇编语句进行解释如下。
STMFD SP!, {R4-R8} //函数执行之前先保存各寄存器的原始值
LDRB R3, [R0] //R3=*R0,加载字节内容到R3
CMP R3, #0x2D //将R3中的值和45进行比较
BEQ loc_B348 //若r3=45则跳转到loc_B348处执行
CMP R3, #0x2B //r3!=45则将其和43进行比较
Mov R6, #0 //r6=0
LDREQB R3, [R0,#1]! //若r3=43则执行LDR操作:R3 = *[R0 + 1]的字节,然后R0更新(即指令执行之后R0=R0+1)
loc_B348:
LDRB R3, [R0,#1]! //若r3=45则执行LDR操作:R3 = *[R0 + 1]的字节,然后R0更新(即指令执行之后R0=R0+1)
Mov R6, #1 //r6=1
B loc_B2Ac
loc_B2Ac:
CMP R3, #0x30 //比较r0+1处的值和48
BNE loc_B2C8 //若r3!=48则跳转到loc_B2C8处执行
ADD R3, R0, #1 //相当于R3=R3+1,此时的R3是一个地址,指向R0的第三个元素
loc_B2B8:
MOV R0, R3 //更新指针R0的值,指向R0起始的字符串(由于每次都取一个字节,所以猜测是字符串,即字符数组)的第三个元素
LDRB R2,[R3], #1 //R2=*r3,r3=r3+1
CMP R2, #0x30 //和48进行比较
BEQ loc_B2B8 //扫描到字符串中不是48的值就向下执行,否则继续扫描下一个字节并判断是否为48(即'0')
loc_B2C8:
MOV R12, #0
MOV R4, #0
MOV R5, #0
MOV R8, #0xA
B loc_B2E4
loc_B2E4:
LDRB R7,[R0,R12] //R7 = *[R0 + R12] = *[R0 + 0],此时R0指向数组中的第一个非零值
ADD R12, R12, #1 //相当于R12=R12+1,即R12++
UMULL R2,R3,R4,R8 //R2=R4*R8的低32位, R3=R4*R8的高32位
SUBS R7, R7, #0x30 //R7=R7-48
BMI loc_B318 //如果SUBS的计算结果为负数(即R7<48),则跳转到loc_B318处,否则顺序执行
CMP R7, #9 //比较数组中的第一个非零值-48和9
MLA R3,R8,R5,R3 //R3 = R8*R5+R3
BGT loc_B318 //若cmp的比较结果是大于则跳转,否则顺序执行
CMP R12, #0xB //这里比较R12和11,相当于在比较循环计数变量,循环次数为11次
BNE loc_B2DC //若不等于则跳转,若等于则执行loc_B30C处的代码
loc_B2DC:
ADDS R4, R2, R7 //R4=R2+R7
ADC R5, R3, R7,ASR#31 //R5=R3+(R7>>31),该代码执行完后跳到分支loc_B2E4执行,这里是一个循环
loc_B30C:
MOV R0, #0 //该代码执行完后跳到分支loc_B310执行
loc_B310: //这部分是函数尾声,执行出栈
和返回操作
LDMFD SP!, {R4-R8}
BX LR
loc_B318:
SUBS R2, R4, R6 //R2=R4-R6
SBC R3, R5, R6,ASR#31
CMP R2, #0x80000000
SBCS R0, R3, #0
BGE loc_B30C
CMP R6, #0